The Mightiest Monolith
Shuttle To SRE — STS Lesson 1
April 12th is a landmark date in space exploration — Yuri Gagarin became the first human to explore outer space in 1961 and Space Shuttle Columbia, the first reusable space craft, was launched on this day in 1981.
While the technology which launched Gagarin into space has a legacy which continues to this day, the Space Shuttle was a departure from space systems which came before it, and its DNA does not seem to have been passed on to further systems.
In this series of lessons we will discuss why this was and what modern developers, DevOps practitioners and Site Reliability Engineers can learn from the Space Shuttle program — its successes and failures.
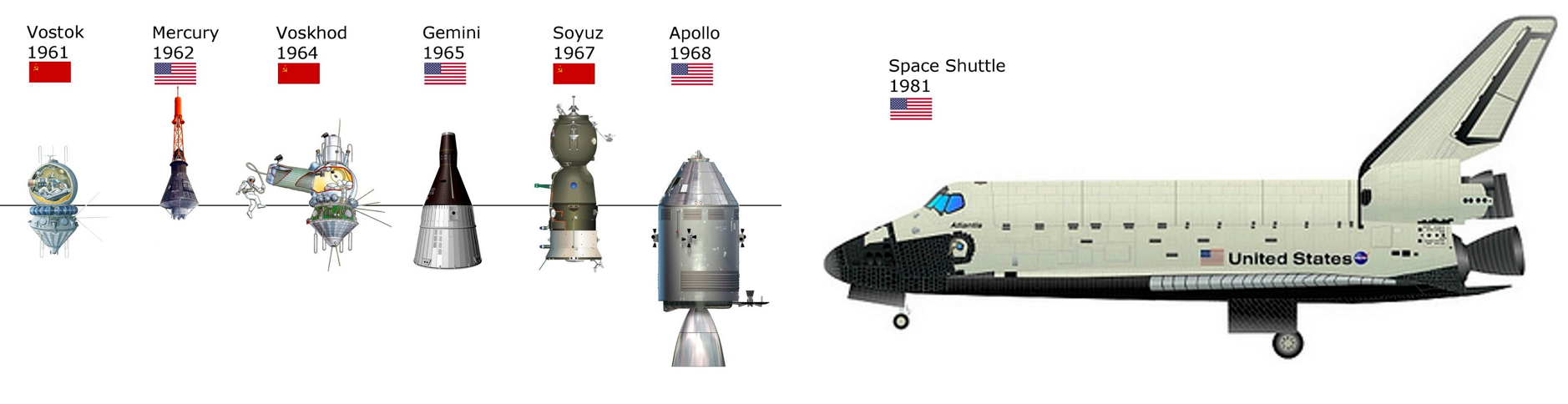
Even the first glance at the Space Shuttle shows how different it is from the spacecraft which preceded it. As discussed in a previous article, both the Americans and the Soviets developed their space programs in an agile fashion: each spacecraft type was larger and more capable than the previous one. In a sense, each spacecraft type was a new version and each mission was was an MVP which added a few new features — developing a dot release in an agile fashion, as it were.
The Shuttle was developed as a completely new solution, which did not continue the Mercury-Gemini-Apollo heritage — a waterfall designed monolith, as it were.
Alan Shepard’s flight, the first American in space, could be called spaceflight version 1.1 while John Glenn, who was the first to orbit the Earth, would be spaceflight version 1.3 and Edward White II would walk in space on the second Gemini mission which would be spaceflight version 2.2. Taking this forward, Neil Armstrong, Buzz Aldrin and Michael Collins reached the Moon on spaceflight version 3.5 (better known as Apollo 11).
The following table shows the list of Apollo Moon landings, the “version” of each flight and the results — as you can see, version 3.11 was much more capable than version 3.05.
This meant that each mission could learn from the previous one and make improvements, because they were building new hardware for each flight. However, even during the height of the Moon landings, NASA officials were thinking of the future of space flight, imagining an era when flying into space, and working in space, would be commonplace and not a new adventure each time: a time when a spaceflight would be “routine” and each new flight would not be a new version with new features, but could be a repeat of the previous one. After all, when new airplanes or trucks come off an assembly line, they don’t go faster or further than the previous ones from the same line!
The promise of the Shuttle, as defined in the 1970s, was to make spaceflight commonplace and cheap. On the one hand, The Shuttle would be a re-usable spacecraft — no more throwing away 99% of the hardware during the flight and placing the remaining 1% in a museum after its flight. The Shuttle would take off and land and take off again. On the other hand, the Shuttle missions would be standardized — astronauts would fly many missions and be experts in flying the shuttle, or launching satellites from the shuttle, or performing medical and industrial experiments in the Shuttle laboratories — but they wouldn’t have to train on a new kind of spacecraft for every new mission.
While every Mercury-Gemini-Apollo flight was an experimental test flight, the Shuttle would be an operational vehicle and no surprises would be expected. This would be like moving from a manual deployment process, where every time we deploy to production we need to be very careful, to a continuous deployment solution, where everything is automated and risk is minimal.
Mean Time Between Flights (MTBF) would not be limited by how fast you could build a new spacecraft, but how fast you could patch up any flight damage and refuel an existing Shuttle. Unlike the commonly defined Mean Time Between Failure (also MTBF), one wanted Shuttle launches to be frequent!.

Reality, though, had other ideas. For a variety of reasons — technological, technical, organizational, cultural and above all, budgetary — the Space Shuttle did not make spaceflight cheap, mundane or even particularly safe. Despite having a fleet of 4 Shuttles (5 in total, but Endevour was built only after the Challenger disaster), NASA was never able to fly Shuttle missions at a faster rate than the Gemini missions of every 2–3 months, even though Gemini was a disposable spacecraft and a new rocket was required for every mission!
Why did the Shuttle not achieve its goals? Why, despite the efforts of thousands of engineers, managers, scientists, astronauts and all the other people involved in the Shuttle program was the Shuttle so expensive and so unreliable?
Many software developers, operators, managers, DevOps practitioners, Site Reliability Engineers (among others) will be familiar with these questions — because we ask each other these questions about our own systems all the time!
While future articles will dig in deeper, let’s look at a few anecdotes which will illustrate the problems which arose even before the first flight 40 years ago on April the 12th:
12-factor apps — Dev/Prod parity
The 12-factors are a series of guidelines, commonly accepted as good practices when developing modern cloud native applications. One of these factors is that your development environment should be as similar as possible to your production environment — identical/in parity if possible.
Now, it’s not feasible to develop a new spacecraft in space. There’s no choice but to build it on Earth. During the 50s and 60s, NASA got around this problem by flying a series of test flights before the first manned mission of any spacecraft type. The first missions were “boilerplate” spacecraft, which simulated the weight and external aerodynamics of the spacecraft. Afterwards came unmanned flights of the spacecraft, where the astronauts were replaced by automated commands. In the Mercury program, the first spacecraft which had the largest amount of unknowns, chimpanzees were sent into space before the astronauts, making the last development flights as close to real flights as possible.
But this was simple, when the spacecraft itself was disposable and could be treated as a customized deployment. In the case of the Shuttle, the very first flight to space (deployment to production) was done by the very first flight-ready vehicle (Columbia). Prior to the launch in 1981, there had been a series of test articles which performed a number of tests — the test vehicle Enterprise flew a series of Approach and Landing Tests which simulated the last few minutes of a Shuttle landing. The Enterprise was hoisted into the sky on the back of a Boeing 747 Jumbo Jet and landed, like the Shuttle would, by gliding onto a runway. But while many valuable lessons were learnt during these flights, they did not cover many of the most critical periods of the mission — liftoff, insertion into orbit, re-entry into Earth’s atmosphere.

So by the time the Shuttle made its first flights, there was no time in the schedule to “go back to the drawing board” and fix issues which were discovered only once the Shuttle was deployed.
Monolithic Solution
While Mercury-Gemini-Apollo all had distinct, clear and specific goals — Mercury to prove that humans could live in space, Gemini to prove that they could work in space and Apollo that they could reach the Moon — the Space Shuttle was supposed to be a long term solution to all of America’s goals in space. The Shuttle would be a universal solution which could deploy all the planned satellites of the United States government and civilian clients, be a flying laboratory for both basic research and experimental industrial experiments, be a repair shop for damaged satellites, a platform for building a space station, allow (relatively) untrained civilians access to space, perform highly secure and secretive missions for the Department of Defense, land on runways around the world, return hardware from space and more!
The shuttle had so many capabilities no single mission could or would use them all!
For example, the shuttle hoisted its entire payload bay into space each and every time it launched, no matter how many satellites it was going to launch or whether there was a full laboratory in it. This meant carrying “empty space” into space. Not to mention bringing all that empty space back, once the satellites were deployed.

This also meant that there was no way of testing that “the Shuttle can be built to deploy satellites efficiently” separately from “the Shuttle can be built to support scientific experimentation”. And certainly no testing of non-functional capabilities (aka “the Shuttle is safe”) separately from the functional ones.
So instead of being a “lean mean spacecraft machine” (i.e. a microservice spacecraft), the Shuttle was a monolithic jack-of-all-trades.
Complexity
The Shuttle ended up being even more complex than the NASA engineers imagined at first. I’ll go over some of these complexities in future articles, but here’s a simple example:

One of the biggest complexities of the Shuttle (which proved to be the downfall of Columbia) was the heat shield. Unlike the spacecraft before it, the shuttle needed a re-usable heat shield. But since the shuttle was so large (it had an enormous payload bay and large wings) there was no suitable material available which could be cast at that scale. So instead of a single heat shield, the shuttle had a series of tiles which protected it from the extreme heat of re-entry. Each tile was numbered and had a unique shape and location where it could fit. After landing, the tiles were examined one by one and any damaged tiles were replaced. This immediately added considerably to the turn-around time of the shuttle flights because the process of checking and repairing the tiles was laborious, delicate, and time consuming — the very definition of unavoidable toil that they never managed to automate away or resolve.

So while the original plan had been to have a heat shield which would allow the re-use of a Shuttle for future flights, the technological limitations and the balance between functional requirements (large body) and non-functional requirements (heat shield covering the entire body) meant that restoring the underside of the Shuttle would limit how fast it could return to flight.

Now despite the trials and tribulations of the Shuttle, and the fact that it did not, in the end, make spaceflight cheap, commonplace or safe, there is certainly no denying that it was a magnificent flying machine and had capabilities that even today, 40 years later, are not part of any current spaceship.
Over the next few articles I will cover more lessons which SREs and DevOps practitioners can learn from the Shuttle. Some will be technical and others, certainly the ones relevant to the Shuttle disasters of Challenger and Columbia, will also be cultural and organizational.
Articles in this series:
For future lessons and articles, follow me here as Robert Barron or as @flyingbarron on Twitter and Linkedin.
Learn more at www.ibm.com/garage
